
DeepSeek Does It Again: From MoE to DSA, The New Era of LLM Efficiency
Header image sourced from Chat-Deep.
Introduction: The Invisible Wall of LLMs
In the fast-paced world of Artificial Intelligence, we often marvel at the size and capabilities of new Large Language Models (LLMs). However, behind every breakthrough lies an invisible wall—a fundamental challenge that limits their scalability and accessibility: computational cost. The team at DeepSeek AI seems to have made tearing down this wall their specialty.
First, they introduced us to their DeepSeek-V2 model with its groundbreaking Mixture-of-Experts (MoE) architecture, a clever way to scale models by activating only a fraction of their parameters for each task. And now, they've done it again. With the release of DeepSeek-V3.2-Exp, they are tackling another pillar holding up that wall: the complexity of the attention mechanism.
The Core Problem: The Tyranny of Quadratic Complexity \(O(L^2)\)
To grasp the magnitude of this innovation, we first need to talk about the enemy: quadratic complexity \(O(L^2)\) within the Transformer's attention mechanism.
Since its inception, attention has allowed models to understand the relationships between words in a text. To do this, each new token being processed must "attend" to every single token that came before it. This is incredibly powerful, but it comes at a cost.
In simple terms, quadratic complexity means that if you double the length of the text (the context), the computational cost and processing time don't just double—they quadruple. If you triple it, the cost multiplies by nine. This creates an exponential bottleneck that makes processing very long documents, entire codebases, or books prohibitively expensive and slow.
The Solution: DeepSeek Sparse Attention (DSA)
DeepSeek-V3.2-Exp introduces an elegant solution to this problem: DeepSeek Sparse Attention (DSA). Instead of "dense" attention (all-to-all), DSA implements "sparse" attention, where each token only attends to the most relevant preceding tokens.
How does it achieve this? The architecture relies on two main components:
- Lightning Indexer: This is the brains of the operation. It's a highly efficient component that, before the main attention calculation, computes an "index score" \(I_{t,s}\) between the current query token and all previous tokens. This score determines relevance. Its design is key to its efficiency, as it uses few heads and can be implemented in FP8.
- Fine-grained Token Selection: Based on the indexer's scores, this mechanism is purely selective. It retrieves only the key-value entries corresponding to the
top-k(the 'k' best) index scores. In the paper, for instance, they mention selecting 2048 key-value tokens for each query.
The result is that the main attention calculation is no longer performed over the entire sequence but on a small, relevant subset of tokens. This changes the game, reducing the attention complexity from \(O(L^2)\) to \(O(Lk)\), where 'k' is a fixed number far smaller than the context length 'L'.
The Results: Radical Efficiency Without Sacrificing Performance
This is where DeepSeek's approach truly shines. This isn't just a theoretical optimization; the results are tangible and, most importantly, achieved without a significant drop in performance.
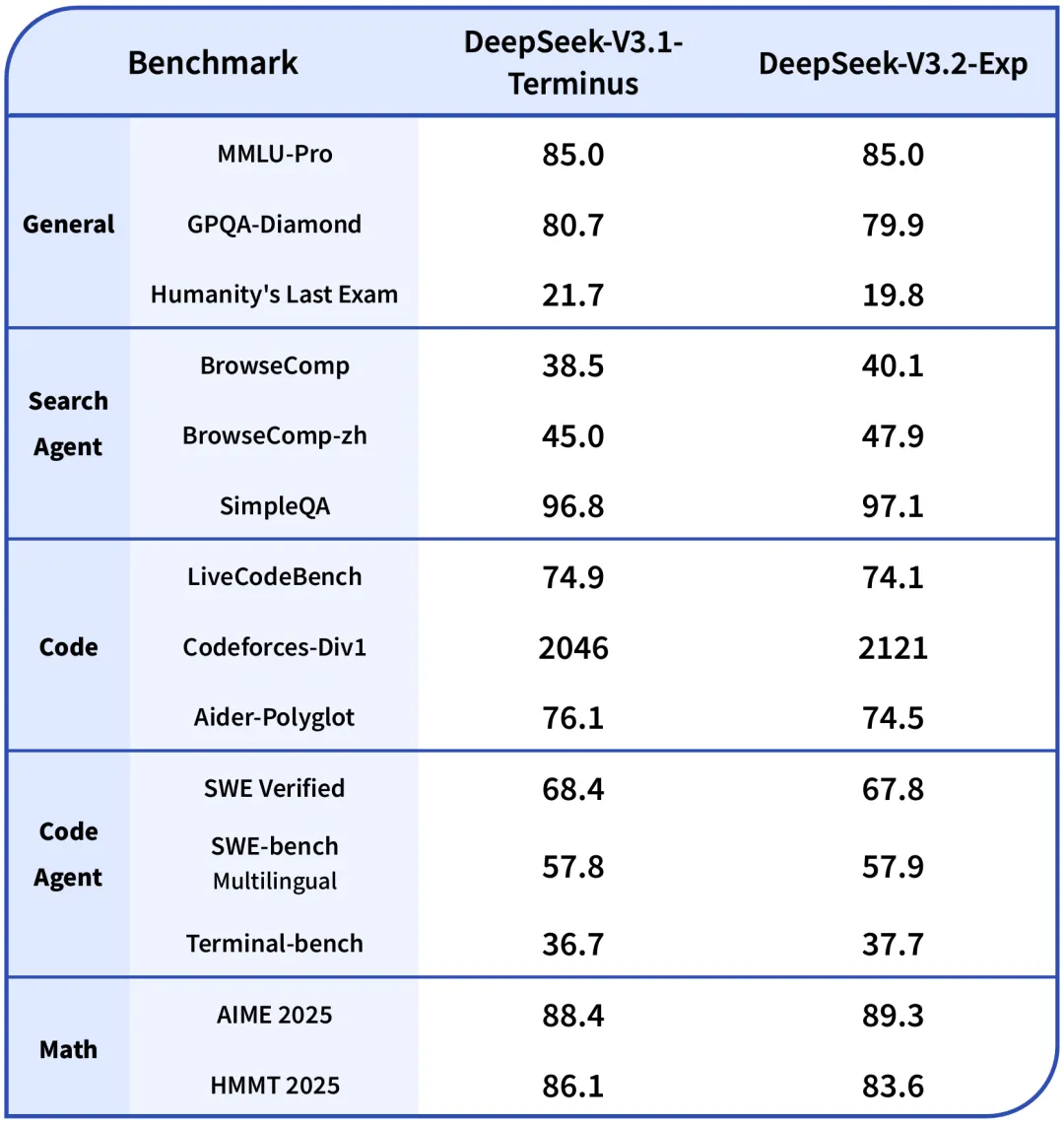
- On-Par Performance: Benchmark comparisons show that DeepSeek-V3.2-Exp does not exhibit substantial performance degradation compared to its predecessor, DeepSeek-V3.1-Terminus. On key benchmarks like MMLU-Pro, the score is identical (85.0), and variations in others are minimal.
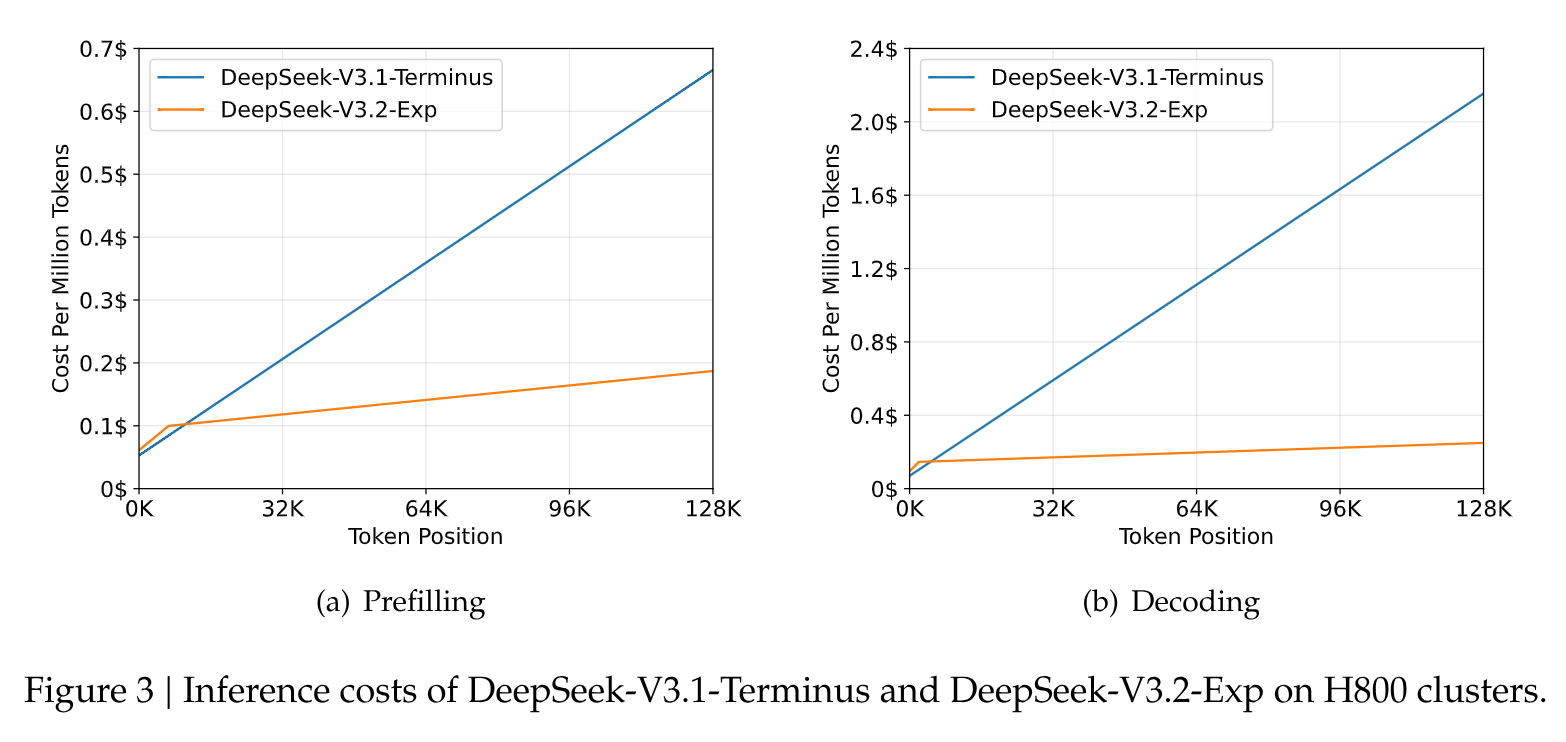
- Drastic Cost Reduction: Figure 3 from the paper is conclusive. It shows how the cost per million tokens—for both prefilling (processing the initial prompt) and decoding (generating the response)—skyrockets linearly for the older model as the context length increases. In contrast, with DSA, the cost curve flattens dramatically, demonstrating massive savings in long-context scenarios.

You can find a more detailed analysis in their paper.

What This Means for the Future
From my perspective, focusing on custom software development and AI implementation, this breakthrough is more than just an incremental improvement; it's an enabler.
- The Era of Hybrid Architectures: DeepSeek is showing us the way forward. The future isn't a single solution but the intelligent combination of efficient architectures. Imagine a model that combines the parameter efficiency of MoE with the context efficiency of DSA. We would be looking at a new generation of LLMs that are fundamentally more scalable and cost-effective.
- New Frontiers for Applications: With lower costs for long-context tasks, use cases that were once prohibitive are now viable. Think of AI agents that can analyze and reason over entire code repositories in real-time, legal assistants that can review thousands of pages of case law instantly, or financial analysis systems that process full annual reports in a single pass.
- The Democratization of Power: Efficiency doesn't just benefit large corporations. Lower training and, crucially, inference costs allow startups, freelance developers, and smaller companies to access and deploy state-of-the-art models to build custom solutions.
Ultimately, DeepSeek is cementing its reputation as a team that doesn't just chase raw performance but tackles the fundamental engineering problems that will allow us to build the next generation of AI applications. And it's fascinating to see how this race for efficiency—driven in part by US hardware restrictions on China—is sparking software innovations that benefit us all. It's the classic story of necessity breeding ingenuity, and in the AI race, architectural ingenuity may prove to be more decisive than the brute force of silicon.
First MoE, now DSA. They are, without a doubt, a team to watch.
What are your thoughts? How do you see these new advancements shaping the future? Leave a comment below!
I'm also leaving a link to their card on Hugging Face so you can dig deeper into this new model.
